LoopixDES Documentation
What is LoopixDES?
LoopixDES is a discrete-event simulator of The Loopix Anonymity System based on the SimPy Python package. The simulator follows a canonical OpenAI Gym Env interface to offer a Reinforcement Learning (RL) challenge. The primary difference is that LoopixDES is a Multi-Objective Optimisation (MOO) problem, unlike classic gym environments.
Installation
$ pip install git+https://github.com/mrybok/loopixdes.git#egg=loopixdesHow to use?
The below code demonstrates the most straightforward training loop in the LoopixEnv environment. The agent and buffer code parts present the possible minimal interface that an RL algorithm could follow, assuming standard Replay Buffer for experience replay. However, the showcased agent interface can vary on an optimising algorithm basis. The codebase does not provide the agent or buffer implementation. Instead, it is the user's task to provide such. Here the agent decides how to tweak the system's parameters (i.e. takes action) with the act method. On the other hand, the agent learns from the accumulated experience with the update method.
from loopixdes.env import LoopixEnvfrom loopixdes.util import load_dataset
agent = Agent()buffer = ReplayBuffer(capacity=int(1e6))traces = load_dataset("path/to/your/dataset.json")env = LoopixEnv()batch_size = 64max_timesteps = 100000episode_length = 2000timesteps_elapsed = 0
while timesteps_elapsed < max_timesteps: state = env.reset(seed=0, options={"traces": traces}) # start new simulation
for _ in range(episode_length): action = agent.act(state) # change Loopix parameters given current state next_state, reward, done, _ = env.step(action) buffer.push(state, action, next_state, reward, [done]) # remember the experience / state transition state = next_state # base the next action on the new state timesteps_elapsed += 1
if len(buffer) >= batch_size: batch = buffer.sample(batch_size) # sample experience and learn from it agent.update(batch)
if done: break # start a new episode if the current ended # start new simulation state = env.reset(seed=0, options={"traces": traces})
for _ in range(episode_length): action = agent.act(state) # change Loopix parameters given current state next_state, reward, done, _ = env.step(action) # remember the experience / state transition buffer.push(state, action, next_state, reward, [done]) state = next_state # base the next action on the new state timesteps_elapsed += 1
if len(buffer) >= batch_size: batch = buffer.sample(batch_size) # sample experience and learn from it agent.update(batch)
if done: break # start a new episode if the current ended
env.close()Dataset
Options
The first example of using the LoopixEnv is limited as it always uses the default simulator settings. The mix network topology does not change between the episodes. The agent does not optimise the payload packet byte size. The simulation always starts from the first Mail in the dataset traces. For a more difficult challenge, change the above between the episodes to create an optimiser robust across different mixnet sizes.
import numpy as nprng = np.random.RandomState(seed)...
while timesteps_elapsed < max_timesteps: # start the next simulation from random mail in the dataset episode_traces = traces[rng.randint(0, len(traces)):] time_offset = traces[0].time
# make the sending times relative to start of the simulation for mail in episode_traces: mail.time -= time_offset
options = { "traces": episode_traces, "init_timestamp": init_timestamp + time_offset, "num_layers": rng.randint(2, 21), # change number of layers for next run "plaintext_size": ..., # set / optimise the byte packet size here }
state = env.reset(seed=0, options=options)
for _ in range(episode_length): action = agent.act(state) ...Rendering
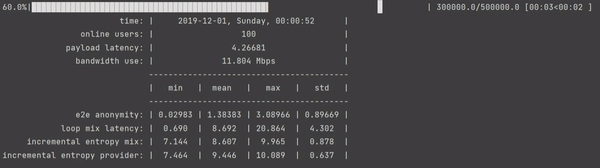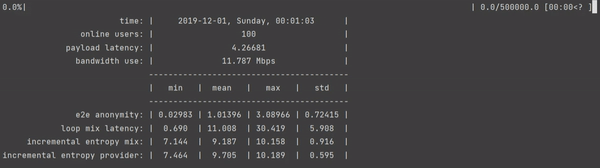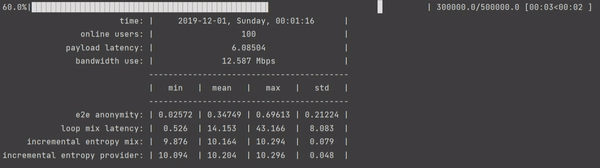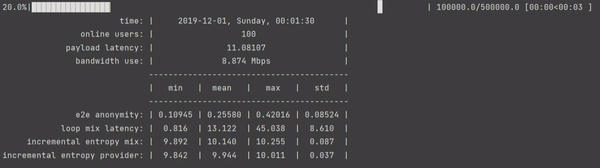
Author
Marcin Rybok
The University of Edinburgh
2022